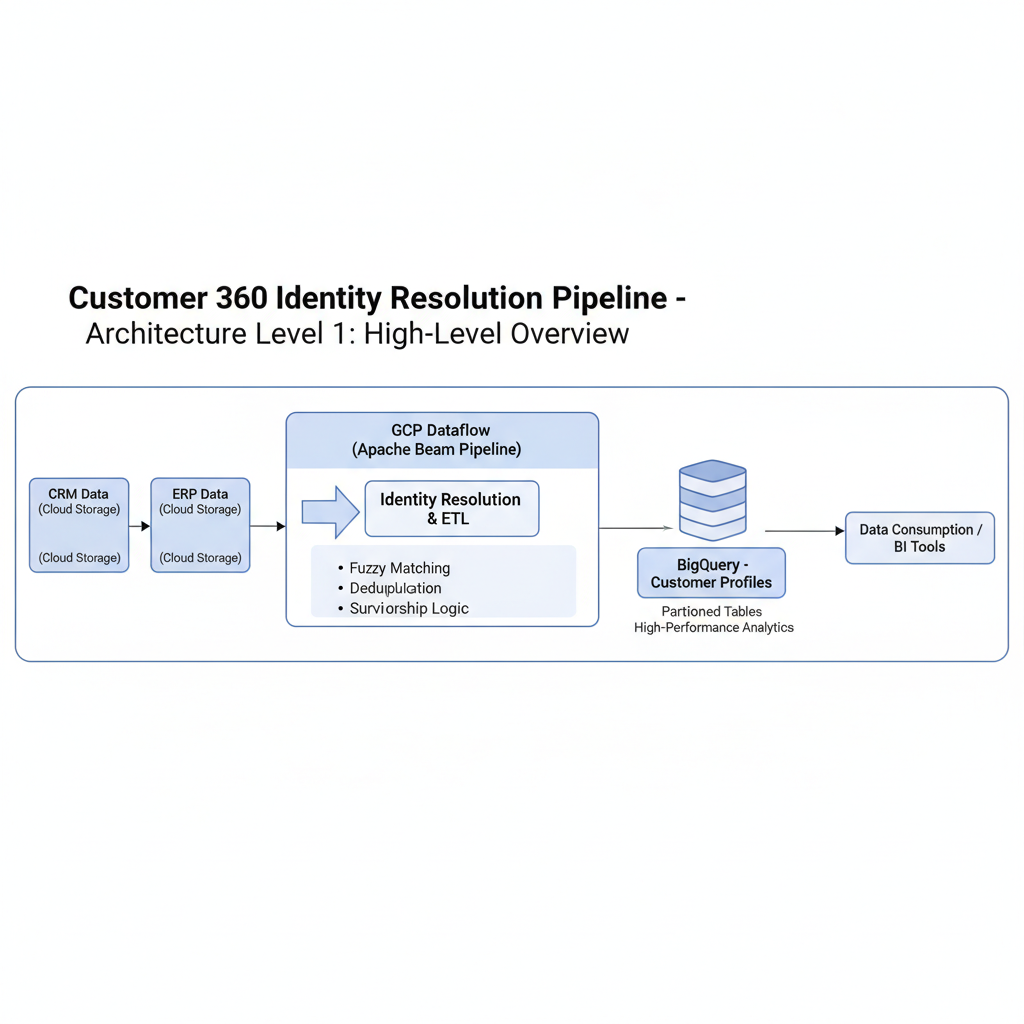
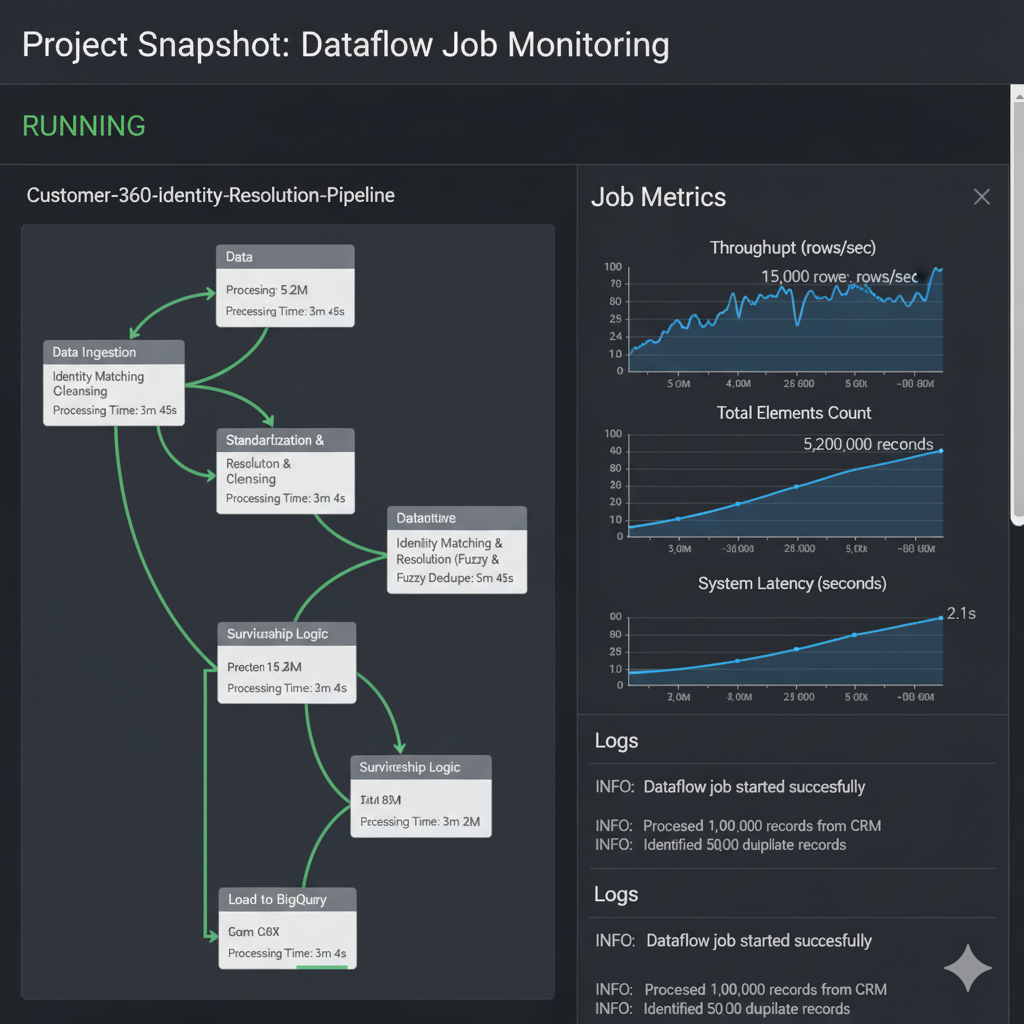
The Customer 360 Identity Resolution Pipeline provides an end-to-end data platform built on Google Cloud Platform (GCP), enabling organizations to unify customer profiles from multiple systems into a single, accurate “golden record.” Using Dataflow (Apache Beam) for ETL, Cloud Storage for ingestion, and BigQuery for warehousing, the solution supports scalable identity matching, deduplication, and enrichment. It handles up to 10 TB initial load, supports 1 GB/day incremental processing, ensures GDPR/CCPA compliance, and offers analytical access through BigQuery views and downstream dashboards.
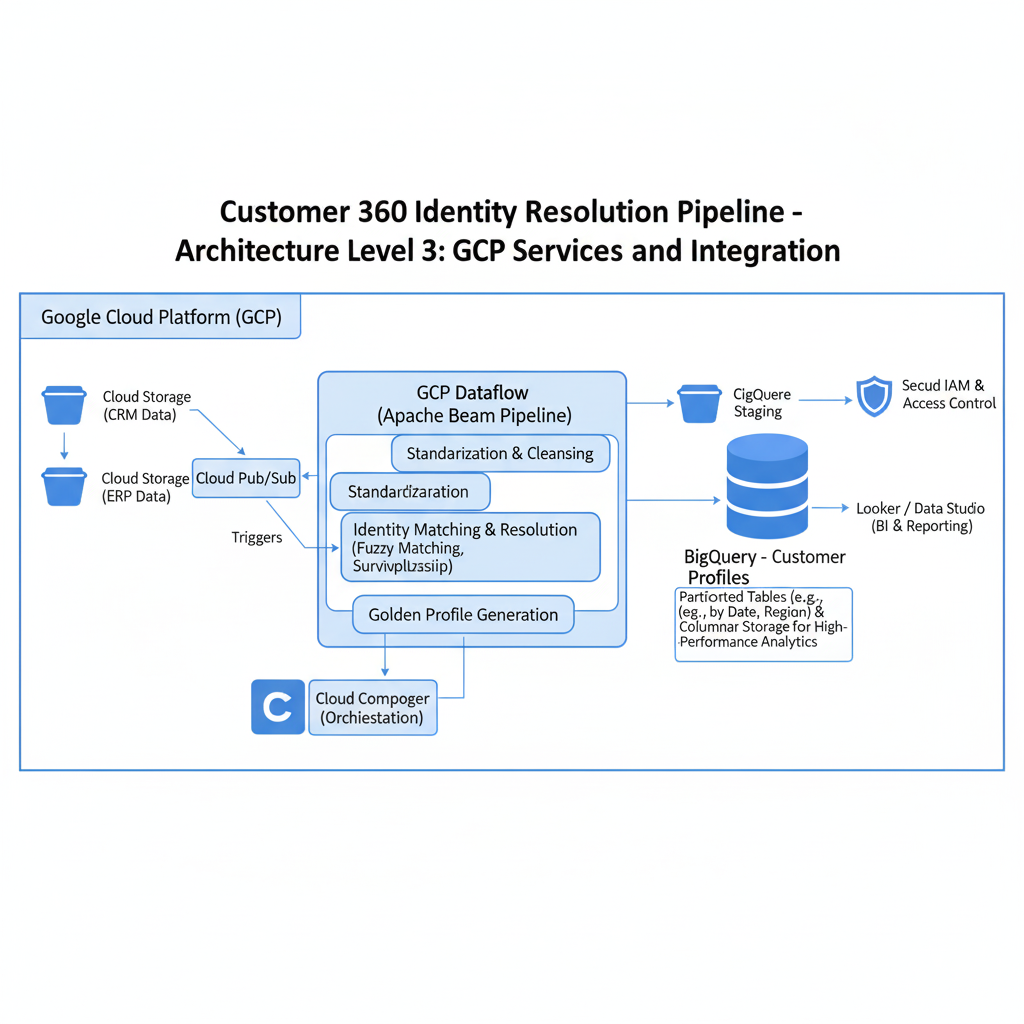
The architecture follows a simple but powerful flow: multiple customer data sources are ingested into Cloud Storage, processed through Dataflow pipelines written in Apache Beam, and loaded into BigQuery datasets. The pipeline performs cleansing, normalization, probabilistic identity matching, and writes unified resolved records into production tables. Monitoring is handled through Cloud Logging, Cloud Monitoring, and Dataflow job metrics. The result is a scalable, automated identity resolution ecosystem optimized for analytics, reporting, and machine learning use cases.
Raw Layer: Schema includes {customer_id, name, email, phone, address, source, timestamp}. Stores unprocessed input from multi-channel systems.
Resolved Layer: Schema includes {master_id, name, email, phone, address, confidence_score, linked_ids}. Stores golden customer records with probabilistic scores.
Partitioning: Partitioned by ingestion date for optimal query performance.
Clustering: Based on customer attributes (e.g., email, phone) to speed resolution queries.
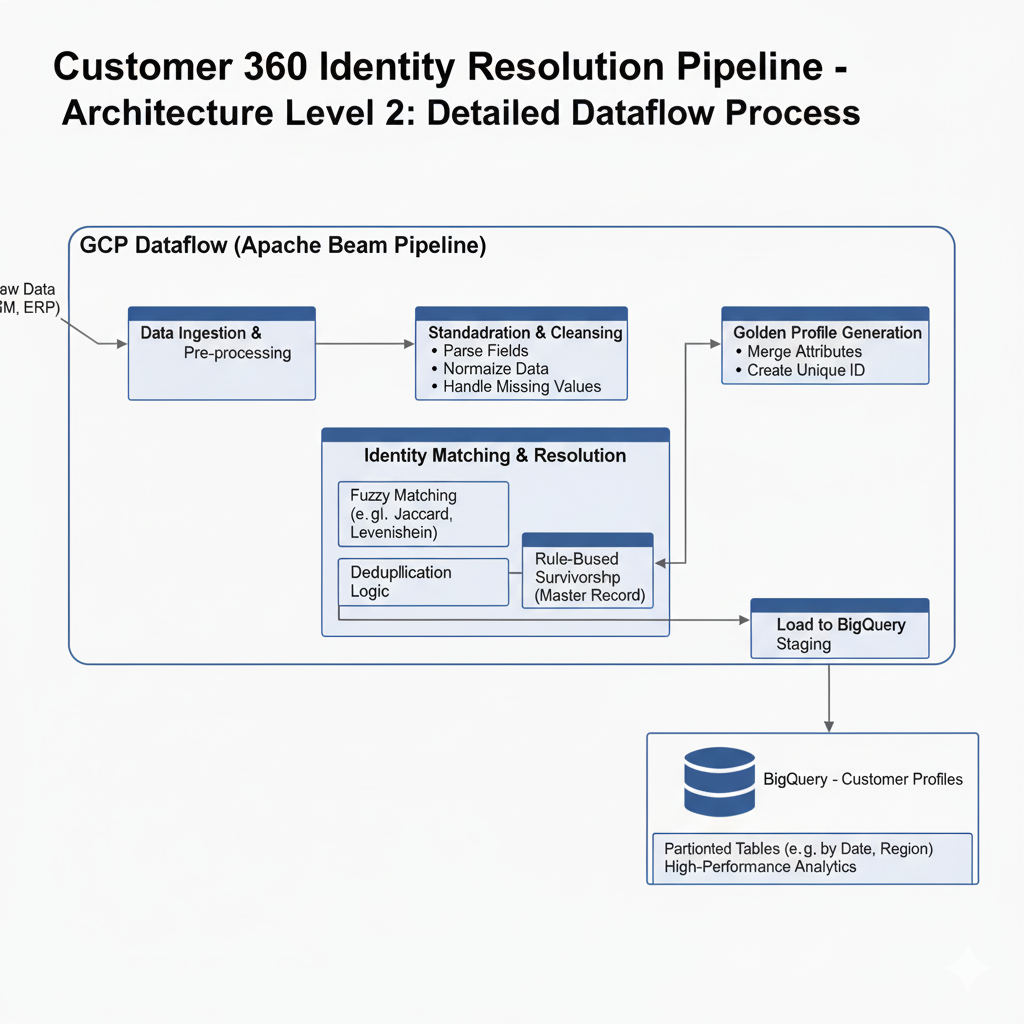
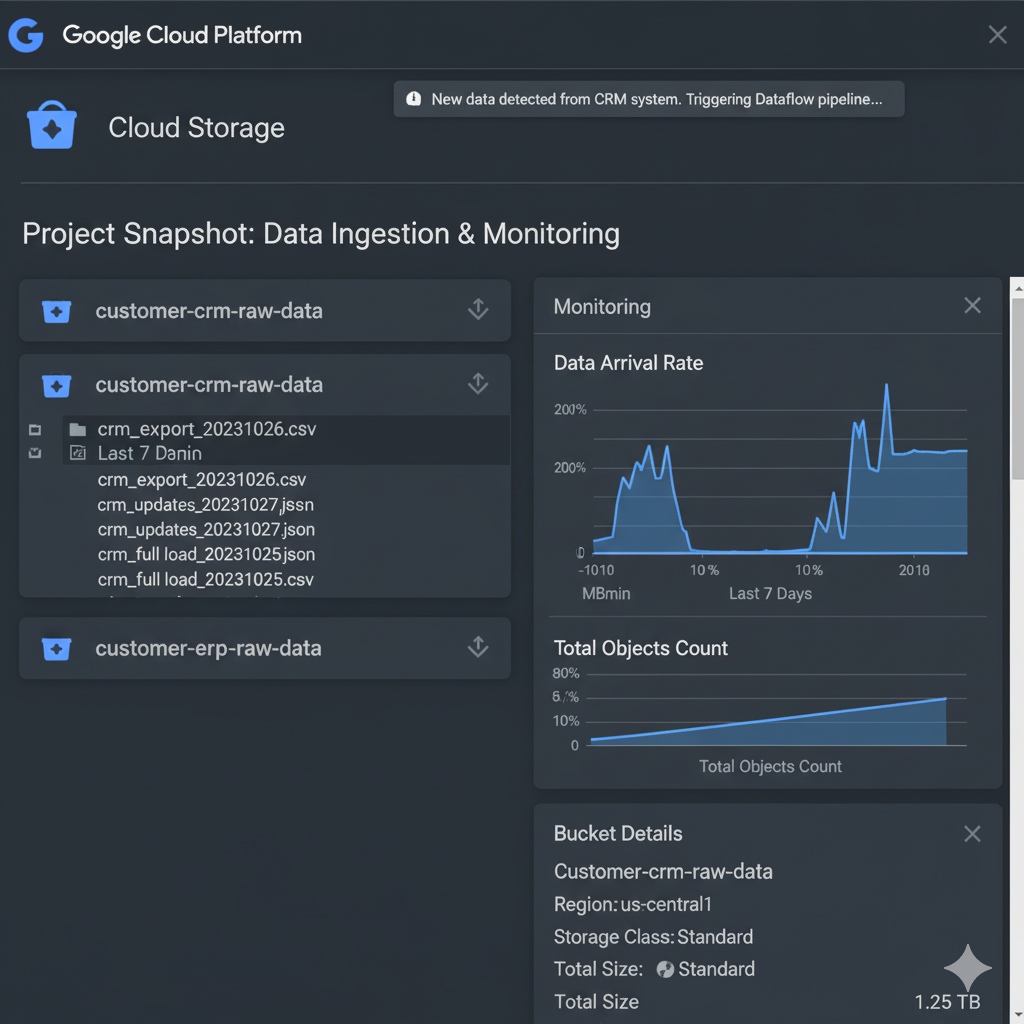
Extract: Read CSV/JSON files from Cloud Storage, with support for ingestion from SFTP, APIs, databases (e.g., MySQL/PostgreSQL).
Transform: Cleaning, standardizing formats, fuzzy matching (e.g., Levenshtein), probabilistic linking, enrichment, and normalization. Errors are routed to dead-letter queues stored in BigQuery.
Load: Write cleaned and resolved records into partitioned BigQuery tables. Downstream consumers access materialized views such as v_unified_customers. This foundation ensures accuracy, automation, and scalable identity resolution across millions of profiles.
Total duration: 12 weeks (Nov 2024 – Feb 2025)
Testing covers Beam unit tests, end-to-end integration tests, data validation (record counts, matching accuracy ≥95%), and performance tests processing 1M records under 30 minutes. Deployment uses Cloud Build, triggered on Git commits, with canary rollout and monitoring dashboards. Backup strategy includes daily BigQuery snapshots and lifecycle policies for Cloud Storage.
Alerts for Dataflow job failures, BigQuery cost monitoring and slot usage, data freshness validation, schema drift detection, and storage lifecycle policies (auto-delete raw after 90 days). This ensures long-term reliability, cost control, and compliance with privacy regulations.
Total team: 1 Data Engineer, 1 Architect, 1 PM with a $50K budget including GCP costs.