The Finance Ledger Harmonization System is a 12-week ETL and data warehousing project designed to ingest, harmonize, and consolidate multi-company financial ledgers into a unified PostgreSQL data warehouse. The solution processes General Ledger (GL) and Trial Balance files, standardizes disparate chart-of-accounts using configurable mapping rules, applies SCD-2 logic for historical tracking, and populates a financial star schema consisting of fact_financial and dim_account tables. Technologies used include PySpark for large-scale transformations, Apache Airflow for orchestration, Hive/Parquet for intermediate storage, and PostgreSQL for the analytical warehouse. The solution achieves reliable ingestion of up to 10 million records per cycle, offers strong auditability, supports daily/weekly batch processing, and enables BI reporting through tools like Power BI and Tableau.
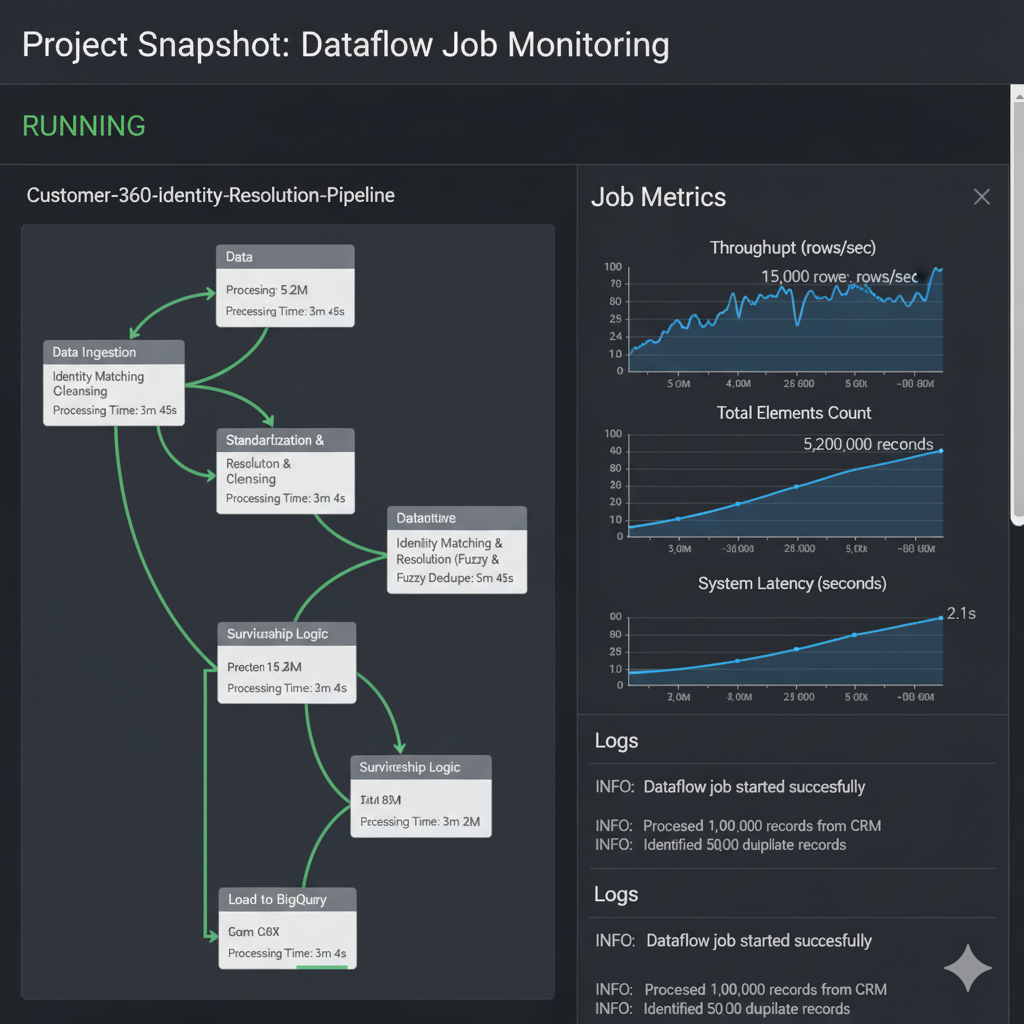
The architecture follows a modular ETL design: Airflow triggers ingestion from multi-company financial files into Hive/Parquet landing zones, PySpark performs harmonization and SCD-2 transformations, and final results are loaded into a PostgreSQL warehouse structured for analytical queries. Airflow handles orchestration and monitoring; Hive acts as an auditable interim storage zone; PySpark applies complex mapping and SCD-2 rules; PostgreSQL hosts the star schema for BI consumption. This architecture ensures data integrity, scalability, historical preservation, and efficient financial reporting.
dim_account (SCD-2): Holds harmonized chart-of-accounts with historical versions. Columns: account_id, natural_account, company_id, account_name, account_type, effective_date, expiry_date, is_current, version. Supports versioned history for audit and compliance.
fact_financial: Contains financial facts per period (balances, debits, credits). Columns: fact_id, account_id, period_date, debit_amount, credit_amount, balance, transaction_type, source_company. Enables period-end reporting and transactional detail analysis.
Data Volumes: Up to 10M records per cycle; 5GB processed in under 30 minutes.
Extract: Airflow ingests CSV/Excel/API-provided GL and TB files from SFTP/S3/local.
Transform: PySpark applies chart-of-accounts harmonization via JSON/YAML mapping rules. Implements SCD-2: hashing attributes, generating new versions, closing old ones. Data quality checks for duplicates, schema mismatches, and balancing (debits = credits).
Load: Dimensional tables loaded into PostgreSQL via JDBC. fact_financial written as incremental snapshots. Intermediate Storage: Parquet layers stored in Hive for auditing and reprocessing. This pipeline ensures idempotency, traceability, and reliable cross-company financial standardization.
Start: Aug 1, 2025 | Dev Complete: Sep 26, 2025 | Go-Live: Oct 31, 2025
Testing included schema validations, reconciliation checks (debits = credits), duplicate detection, performance testing on 15GB datasets (processed in 25 minutes), and UAT validation. Airflow DAGs were tested in isolated dev environments before production rollout. Deployment used CI/CD via Jenkins, SSL-secured JDBC connections, and Airflow environment promotion (dev → staging → prod). Rollback supported through Hive staging backups and PostgreSQL snapshots.
Monitoring includes Airflow DAG tracking (success/failure rates, retries), Prometheus metrics for Spark executor usage, and Slack notifications for pipeline failures. Data quality reports are generated per cycle. Security controls: role-based access, SSL encryption, anonymized dev data. Scalability is achieved through Spark dynamic allocation and Parquet partitioning by period/company. The system maintains 99.9% reliability and provides transparent audit trails.
Total Project Team: 5 members | Methodology: Agile Sprints
Tools used: Git, Jenkins, Airflow, Spark, PostgreSQL, Hive
.png)
.png)
.png)